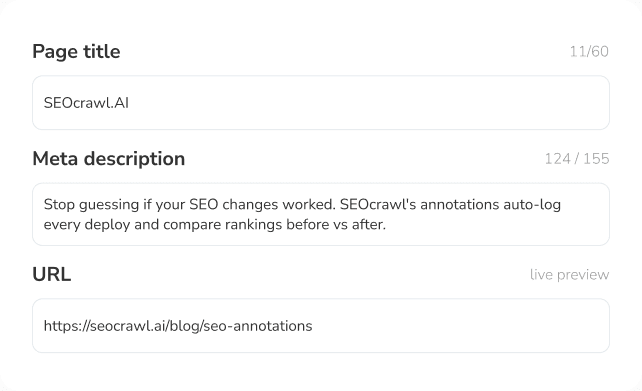
Vérificateur robots.txt bots IA : découvrez quels crawlers IA vous autorisez
Collez votre domaine et nous lisons votre robots.txt pour vous montrer — bot par bot — si vous autorisez ou bloquez GPTBot, ClaudeBot, Google-Extended, PerplexityBot et tous les autres grands crawlers IA. Découvrez si vous êtes visible dans la recherche IA avant vos concurrents. Sans inscription.
Gratuit, sans inscription. Nous lisons votre robots.txt et vous montrons quels crawlers IA — GPTBot, ClaudeBot, Google-Extended, PerplexityBot et plus — vous autorisez ou bloquez en ce moment.
Pourquoi les bots IA dans votre robots.txt comptent pour votre visibilité
Votre robots.txt est la première chose que lit un crawler, et les entreprises d'IA exploitent désormais leurs propres crawlers avec leurs propres noms de user-agent. OpenAI à elle seule utilise GPTBot pour l'entraînement, OAI-SearchBot pour ChatGPT Search et ChatGPT-User pour les requêtes à la demande. Anthropic, Google, Perplexity, Common Crawl et d'autres ont chacun les leurs. Une seule règle Disallow décide si votre contenu peut alimenter ces systèmes et y être cité.
Vous tromper dans un sens comme dans l'autre vous coûte cher : bloquez les crawlers de recherche et votre marque disparaît des réponses IA ; laissez les crawlers d'entraînement ouverts alors que vous vouliez vous en exclure et votre contenu entraîne gratuitement des modèles. Une vérification rapide vous indique exactement où vous en êtes avec chaque grand bot IA.
Comment interpréter votre résultat
Autorisé
Le crawler peut accéder à la racine de votre site. Pour les bots de recherche IA comme OAI-SearchBot, ClaudeBot et PerplexityBot, c'est ce qui vous maintient éligible pour être cité dans les réponses IA.
Partiel
Le crawler peut atteindre votre site, mais votre robots.txt lui interdit certains chemins. C'est généralement sans problème : vérifiez simplement que vous ne masquez pas des pages que vous voulez voir apparaître dans la recherche IA.
Bloqué
Une règle Disallow: / arrête ce crawler dès la porte. Intentionnel pour s'exclure de l'entraînement, mais problématique s'il s'agit d'un crawler de recherche pour lequel vous vouliez rester visible.
Erreurs courantes dans robots.txt — et comment les corriger
Bloquer la recherche IA par accident.
Un Disallow général qui attrape OAI-SearchBot ou PerplexityBot vous retire silencieusement des réponses IA. Autorisez les crawlers de recherche et ne bloquez que les bots d'entraînement si nécessaire.
Se fier à User-agent: * pour l'IA.
De nombreux crawlers IA ignorent le groupe joker et n'obéissent qu'à une règle nommant leur token exact. Ciblez chaque bot IA par son user-agent spécifique.
Confondre Google-Extended et Googlebot.
Bloquer le mauvais token laisse l'entraînement IA actif, ou vous désindexe par mégarde de la recherche. Utilisez Google-Extended pour l'IA et Googlebot pour la recherche.
Considérer robots.txt comme un pare-feu.
Robots.txt est indicatif : il n'arrêtera pas les crawlers qui choisissent de l'ignorer ni le scraping via des tiers. Utilisez un blocage côté serveur pour les bots que vous devez vraiment stopper.
Suivez votre marque dans les réponses IA
Autoriser les crawlers IA n'est que la première étape. L'AI Tracker de SEOcrawl vous montre la suite : il surveille à quelle fréquence ChatGPT, Claude, Gemini et Perplexity mentionnent et citent réellement votre marque, quels prompts vous déclenchent et comment vous vous situez face à vos concurrents — le tout à côté de vos données Google Search Console, au même endroit.
Questions fréquentes
Qu'est-ce qu'un vérificateur de bots IA ?
Un vérificateur de bots IA lit le fichier robots.txt d'un site et vous indique quels crawlers IA il autorise ou bloque à cet instant. Il confronte les tokens de user-agent des principales entreprises d'IA — OpenAI (GPTBot, OAI-SearchBot, ChatGPT-User), Anthropic (ClaudeBot, Claude-SearchBot), Google (Google-Extended), Perplexity (PerplexityBot), Common Crawl (CCBot) et d'autres — aux règles Allow et Disallow de votre robots.txt.
Comment bloquer les crawlers IA dans robots.txt ?
Ajoutez un groupe par crawler avec une règle Disallow, par exemple "User-agent: GPTBot" suivi de "Disallow: /". Pour en bloquer plusieurs, listez chaque user-agent dans son propre groupe. Rappelez-vous que robots.txt est indicatif : des crawlers bien élevés comme GPTBot et ClaudeBot le respectent, mais ce n'est pas un mécanisme contraignant, il n'arrêtera donc pas les bots qui choisissent de l'ignorer.
Faut-il bloquer ou autoriser les bots IA ?
Cela dépend de votre objectif. Bloquer les crawlers d'entraînement (GPTBot, CCBot, Google-Extended) exclut votre contenu de l'entraînement des modèles. Mais bloquer les crawlers de recherche IA (OAI-SearchBot, ClaudeBot, PerplexityBot) peut tenir votre marque à l'écart des réponses de ChatGPT, Claude et Perplexity, vous coûtant en visibilité et en trafic de référence. De nombreux sites autorisent les crawlers de recherche tout en bloquant uniquement ceux d'entraînement.
Bloquer Google-Extended nuit-il à mon classement Google ?
Non. Google-Extended contrôle uniquement si votre contenu est utilisé pour entraîner et ancrer Gemini et Vertex AI. Il est distinct de Googlebot, donc bloquer Google-Extended n'a aucun effet sur votre classement dans la recherche Google. C'est la façon propre de vous exclure de l'entraînement IA sans toucher à la recherche organique.
Quelle est la différence entre les bots IA d'entraînement, de recherche et à la demande ?
Les bots d'entraînement (GPTBot, CCBot, Google-Extended, Bytespider) explorent le contenu pour entraîner des modèles. Les bots de recherche (OAI-SearchBot, Claude-SearchBot, PerplexityBot) indexent votre site afin qu'il puisse être cité dans les réponses de recherche IA. Les bots à la demande (ChatGPT-User, Claude-User, Perplexity-User) récupèrent une seule page en temps réel lorsqu'un utilisateur interroge l'assistant à son sujet. Bloquer chacun d'eux a des conséquences très différentes sur votre visibilité IA.